Some Kaldi Notes
![]()
Documentation
Here’s some documentation I’ve been working on as a walk-through of a typical Kaldi run.sh script.
Bayes Rule and ASR
This is from a slide in the first set of slides from Dan Povey’s lectures on using Kaldi.
\[P(\text{ utterance } \vert \text{ audio })=\frac{p(\text{ audio } \vert \text{ utterance }) \cdot P(\text{ utterance })}{p(\text{ audio })}\]- \(P(\text{ utterance })\) comes from our language model (i.e. n-gram)
- \(p(\text{ audio } \vert \text{ utterance })\) is a sentence-dependent statistical model of audio production, trained from data
- Given a test utterance, we pick ‘utterance’ to maximize \(P(\text{ utterance } \vert \text{ audio })\).
- Note: \(p(\text{ audio })\) is a normalizer that doesn’t matter
WFST Key Concepts
- determinization
- minimization
- composition
- equivalent
- epsilon-free
- functional
- on-demand algorithm
- weight-pushing
- epsilon removal
HMM Key Concepts
- Markov Chain
- Hidden Markov Model
- Forward-backward algorithm
- Viterbi algorithm
- E-M for mixture of Gaussians
L.fst: The Phonetic Dictionary FST
L maps monophone sequences to words.
The file L.fst is the Finite State Transducer form of the lexicon with phone symbols on the input and word symbols on the output.
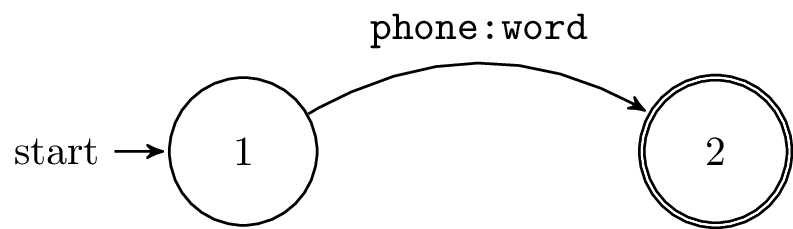
See “Speech Recognition with Weighted Finite-State Transducers” by Mohri, Pereira and Riley, in Springer Handbook on SpeechProcessing and Speech Communication, 2008 for more information.
Here’s an example with two words:

The following section comes from the documentation.
The structure of the lexicon is roughly as one might expect. There is one state (the “loop state”) which is final. There is a start state that has two transitions to the loop state: one with silence and one without. From the loop state there is a transition corresponding to each word, and that word is the output symbol on the transition; the input symbol is the first phone of that word. It is important both for the efficiency of composition and the effectiveness of minimization that the output symbol should be as early as possible (i.e. at the beginning not the end of the word). At the end of each word, to handle optional silence, the transition corresponding to the last phone is in two forms: one to the loop state and one to the “silence state” which has a transition to the loop state. We don’t bother putting optional silence after silence words, which we define as words that have just one phone that is the silence phone.
L_disambig.fst: The Phonetic Dictionary with Disambiguation Symbols FST
A lexicon with disambiguation symbols, see Mohri etal’s work for more info.
In general, you need to have disambiguation symbols when you have one word that is a prefix of another (cat and cats in the same lexicon would need to have cat being pronounced “k ae t #1”) or a homophone of another word (red: “r eh d #1”, read: “r eh d #2”). If you don’t have these then the models become nondeterministic.
Symbols like #1 and #2 that go on the ends of words to ensure determinizability.
G.fst: The Language Model FST
FSA grammar (can be built from an n-gram grammar).
C.fst: The Context FST
C maps triphone sequences to monophones.
Expands the phones into context-dependent phones.
H.fst: The HMM FST
H maps multiple HMM states (a.k.a. transition-ids in Kaldi-speak) to context-dependent triphones.
Expands out the HMMs. On the right are the context-dependent phones and on the left are the pdf-ids.
HCLG.fst: final graph
mkgraph.sh: Graph compilation
This script creates a fully expanded decoding graph (HCLG) that represents the language-model, pronunciation dictionary (lexicon), context-dependency, and HMM structure in our model. The output is a Finite State Transducer that has word-ids on the output, and pdf-ids on the input (these are indexes that resolve to Gaussian Mixture Models).
The following files are required:
lang/
L.fst
G.fst
phones.txt
words.txt
phones/
silence.csl
disambig.int
exp/
mono0a/
final.mdl
treehttp://kaldi.sourceforge.net/graph_recipe_test.html
OpenFst Symbol Tables
Both words.txt and phones.txt are OpenFst Symbol Tables
From openfst.org:
Symbol (string) to int and reverse mapping.
The SymbolTable implements the mappings of labels to strings and reverse. SymbolTables are used to describe the alphabet of the input and output labels for arcs in a Finite State Transducer.
SymbolTables are reference counted and can therefore be shared across multiple machines. For example a language model grammar G, with a SymbolTable for the words in the language model can share this symbol table with the lexical representation L o G.
For every FST the symbol ‘0’ is reserved for \(\epsilon\).
words.txt
An OpenFst symbol table.
The file words.txt is created by prepare_lang.sh and is a list of all words in the vocabulary, in addition to silence markers, and the disambiguation symbol “#0” (used for epsilon on the input of G.fst).
Each word has a unique number.
<eps> 0
<SIL> 1
<unk> 2
а 3
аа 4
.
.
.
өөрчүшөт 64714
өөрөнүнөн 64715
#0 64716
<s> 64717
</s> 64718phones.txt
<eps> 0
SIL 1
SIL_B 2
SIL_E 3
SIL_I 4
SIL_S 5
SPOKEN_NOISE_B 6
SPOKEN_NOISE_E 7
SPOKEN_NOISE_I 8
SPOKEN_NOISE_S 9
a_B 10
a_E 11
.
.
.
zh_I 132
zh_S 133
#0 134
#1 135
#2 136
#3 137
#4 138
#5 139oov.txt
This file has a single line with the word (not the phone!) for out of vocabulary items.
In my case I’m using “<unk>” because that’s what I get from IRSTLM in my language model (task.arpabo), and this entry has to be identical to that.
Tree Info
In the below simple acoustic model, I have 25 phones. I have a 3-state HMM typology for non-silence phones, and a 5-state typology for silence phones. Since I have 24 non-silence phones, and only one silence phone, I get:
(24 x 3) + (1 x 5) = 77
77 total states in the acousitc model.
josh@yoga:~/git/kaldi/egs/kgz/kyrgyz-model$ ../../../src/gmmbin/gmm-info exp/monophones/final.mdl
../../../src/gmmbin/gmm-info exp/monophones/final.mdl
number of phones 25
number of pdfs 77
number of transition-ids 162
number of transition-states 77
feature dimension 39
number of gaussians 499Looking at the decision tree for a monophone model, we see there is one pdf per state.
josh@yoga:~/git/kaldi/egs/kgz/kyrgyz-model$ ../../../src/bin/tree-info exp/monophones/tree
../../../src/bin/tree-info exp/monophones/tree
num-pdfs 77
context-width 1
central-position 0You can easily visualize a tree with Kaldi’s draw-tree.cc and dot:
josh@yoga:~/git/kaldi/egs/kgz/kyrgyz-model$ ../../../src/bin/draw-tree data_no_voice/lang/phones.txt exp_no_voice/triphones/tree | dot -Gsize=8,10.5 -Tps | ps2pdf - ./mono-tree.pdf
../../../src/bin/draw-tree data_no_voice/lang/phones.txt exp_no_voice/triphones/tree We end up with a nice graph in the file mono-tree.pdf:

Working with Alignments (Phone or Word)
# convert alignments to ctm
../../wsj/s5/steps/get_train_ctm.sh data_org/train/ data_org/lang exp_org/monophones_aligned/
# print alignments to human readable format
../../../../../src/bin/show-alignments ../../data_chv/lang/phones.txt final.mdl ark:"gunzip -c ali.2.gz |" > ali.2.txttraining fsts graphs
# foo here is a file that contains one uttID
echo "17385-0003"> foo.txt
# compile that one graph
../../../src/bin/compile-train-graphs exp_chv/monophones/tree exp_chv/monophones/0.mdl data_chv/lang/L.fst 'ark:utils/sym2int.pl --map-oov 267 -f 2- data_chv/lang/words.txt < foo.txt|' 'ark:exp_chv/monophones/test.fst'
# get rid of its utt id at the beginning of file and print
sed "s/17385-0003 //g" exp_chv/monophones/test.fst | ../../../tools/openfst-1.6.2/bin/fstprint --osymbols=data_chv/lang/words.txt --isymbols=data_chv/lang/phones.txt
0 6 а <eps> 0.693359375
0 7 б <eps> 0.693359375
0 8 в <eps> 0.693359375
0 0.693359375
1 9 д <eps>
1 10 е <eps>
1 11 ж <eps>
2 12 з <eps>
2 13 й <eps>
2 14 к <eps>
3 15 л <eps>
3 16 м <eps>
3 17 о <eps>
4 5 р <eps>
5 5 п <eps>
5
6 1 <eps> <eps>
6 6 SIL <eps>
7 2 <eps> <eps>
7 7 SIL <eps>
8 3 <eps> <eps>
8 8 SIL <eps>
9 2 <eps> <eps>
9 9 г <eps>
10 3 <eps> <eps>
10 10 г <eps>
11 4 <eps> <eps>
11 11 г <eps>
12 1 <eps> <eps>
12 12 и <eps>
13 3 <eps> <eps>
13 13 и <eps>
14 4 <eps> <eps>
14 14 и <eps>
15 1 <eps> <eps>
15 15 н <eps>
16 2 <eps> <eps>
16 16 н <eps>
17 4 <eps> <eps>
17 17 н <eps>Choose one training utt
# working with a reletively short utterance, look at its transcription
$ grep atai_354 input_org/transcripts
atai_354 сокого таар жаап койчуWord Level alignment
# this creates the ctm file
$ steps/get_train_ctm.sh data_org/train/ data_org/lang exp_org/monophones_aligned/
# pull out one utt from ctm file
$ grep atai_354 exp_org/monophones_aligned/ctm
atai_354 1 0.270 0.450 сокого
atai_354 1 0.720 0.420 таар
atai_354 1 1.140 0.330 жаап
atai_354 1 1.470 0.510 койчу Phone level alignments ( CTM style )
$ ali-to-phones --ctm-output exp_org/monophones_aligned/final.mdl ark:"gunzip -c exp_org/monophones_aligned/ali.2.gz |" -> ali.2.ctm ; grep "atai_354" ali.2.ctm
atai_354 1 0.000 0.270 1
atai_354 1 0.270 0.100 22
atai_354 1 0.370 0.090 18
atai_354 1 0.460 0.060 13
atai_354 1 0.520 0.100 18
atai_354 1 0.620 0.050 8
atai_354 1 0.670 0.050 18
atai_354 1 0.720 0.150 24
atai_354 1 0.870 0.070 3
atai_354 1 0.940 0.140 3
atai_354 1 1.080 0.060 21
atai_354 1 1.140 0.110 29
atai_354 1 1.250 0.050 3
atai_354 1 1.300 0.060 3
atai_354 1 1.360 0.110 20
atai_354 1 1.470 0.050 13
atai_354 1 1.520 0.050 18
atai_354 1 1.570 0.040 12
atai_354 1 1.610 0.180 5
atai_354 1 1.790 0.190 25
atai_354 1 1.980 0.420 1Pretty phone alignments
$ show-alignments data_org/lang/phones.txt exp_org/monophones_aligned/final.mdl ark:"gunzip -c ali.1.gz |" | grep "atai_354"
atai_354 [ 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 12 18 17 17 17 ] [ 140 139 139 142 141 144 143 143 143 143 ] [ 116 115 118 117 120 119 119 119 119 ] [ 86 85 85 88 90 89 ] [ 116 115 115 118 117 117 117 117 120 119 ] [ 56 58 60 59 59 ] [ 116 118 117 117 120 ] [ 152 151 151 151 151 151 151 151 154 153 156 155 155 155 155 ] [ 26 28 27 27 27 27 30 ] [ 26 28 27 27 27 27 27 27 27 27 27 27 27 30 ] [ 134 133 133 133 136 138 ] [ 182 184 183 183 183 183 186 185 185 185 185 ] [ 26 25 28 27 30 ] [ 26 28 27 27 30 29 ] [ 128 127 127 127 127 130 129 129 132 131 131 ] [ 86 85 88 90 89 ] [ 116 115 118 120 119 ] [ 80 79 82 84 ] [ 38 37 37 37 37 37 37 40 39 39 39 39 39 39 42 41 41 41 ] [ 158 157 157 157 157 160 162 161 161 161 161 161 161 161 161 161 161 161 161 ] [ 4 1 1 1 1 1 1 1 16 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 18 ]
atai_354 SIL s o k o g o t a a r zh a a p k o j ch u SIL Print the Training graph for one utterance
# make a file that contains one uttID
echo "atai_354"> utt.id
# compile that one graph
$ compile-train-graphs exp_org/monophones/tree exp_org/monophones/0.mdl data_org/lang/L.fst 'ark:utils/sym2int.pl --map-oov 267 -f 2- data_org/lang/words.txt < utt.id|' 'ark:mynew.fst'
# get rid of its utt id at the beginning of file and print
sed "s/atai_354 //g" mynew.fst | fstprint --isymbols=data_org/lang/phones.txt --osymbols=data_org/lang/words.txt Other Blogs
Here’s “Kaldi For Dummies”.
Here’s a good blog.
Here’s a good tutorial.
Another tutorial.