How to Add a Language to eSpeak NG
Introduction
ESpeak NG is an open-source, formant speech synthesizer which has been integrated into various open-source projects (e.g. Ubuntu, NVDA). ESpeak NG can be also be used as a stand-alone text-to-speech converter to read text out loud on a computer. ESpeak NG is the ‘New Generation’ fork of the older, eSpeak.
To add a new language to eSpeak NG, you need to have an understanding of the sounds of the language you’re interested in. Knowledge of programming, while helpful, is not necessarily needed.
Specifically, you need to know two things: (1) how the sounds of the language work, and (2) how the spelling of the language relates to those sounds.
There is indeed good documentation out there already on how to add a new language to eSpeak NG (and a lot of the information in this post comes directly from the official documentation). I decided to create yet another set of instructions, because in my experience of adding the Kyrgyz langauge to eSpeak NG, it took a while to digest some of the steps and links, and what I’ve written here is a version that makes sense to me.
In adding a new language, these are the files that you will need to edit or create. In the following table, new-language refers to the full name of the language you’re working on (e.g. in my case, this will be kyrgyz). The word family refers to the directory of the language family (e.g. in my case trk because Kyrgyz is a Turkic language). Finally, the two letters nl refer to the international two letter code of the new langauge you’re adding (e.g. in my case, ky).
| path/file | action |
|---|---|
| ./Makefile.am | edit |
| ./phsource/phonemes | edit |
| ./phsource/ph_new-language | create |
| ./dictsource/nl_extra | create |
| ./dictsource/nl_list | create |
| ./dictsource/nl_rules | create |
| ./espeak-data/voices/family/nl | create |
Installing eSpeak NG
First, let’s clone eSpeak NG from Github:
josh@yoga:~/Desktop$ git clone https://github.com/espeak-ng/espeak-ng.git
Cloning into 'espeak-ng'...
remote: Counting objects: 26919, done.
remote: Total 26919 (delta 0), reused 0 (delta 0), pack-reused 26919
Receiving objects: 100% (26919/26919), 37.95 MiB | 1.56 MiB/s, done.
Resolving deltas: 100% (18206/18206), done.
Checking connectivity... done.Now that we’ve got it downloaded, let’s take a peek into the folder and see what we’ve got:
josh@yoga:~/Desktop$ cd espeak-ng/
josh@yoga:~/Desktop/espeak-ng$ la
autogen.sh COPYING espeak-data .gitignore phsource .travis.yml
CHANGELOG.md dictsource espeak-ng.pc.in _layouts README.md vim
configure.ac docs .git Makefile.am srcNow that we’ve got everything downloaded and in place, we run the autogen.sh shell script. This is a very short script whose main function is to call three of the GNU Autotools: autoheader (which helps configure work smoothly), automake (generates the Makefiles) and autoconf (generates the configure file).
josh@yoga:~/Desktop/espeak-ng$ ./autogen.sh
libtoolize: putting auxiliary files in `.'.
libtoolize: linking file `./ltmain.sh'
libtoolize: putting macros in AC_CONFIG_MACRO_DIR, `m4'.
libtoolize: linking file `m4/libtool.m4'
libtoolize: linking file `m4/ltoptions.m4'
libtoolize: linking file `m4/ltsugar.m4'
libtoolize: linking file `m4/ltversion.m4'
libtoolize: linking file `m4/lt~obsolete.m4'
configure.ac:4: installing './compile'
configure.ac:4: installing './config.guess'
configure.ac:4: installing './config.sub'
configure.ac:3: installing './install-sh'
configure.ac:3: installing './missing'
Makefile.am: installing './INSTALL'
Makefile.am: installing './depcomp'Now, we’re ready to configure. The ./configure script basically checks to make sure that everything is ready to compile.
josh@yoga:~/Desktop/espeak-ng$ ./configure --prefix=/usr
checking for a BSD-compatible install... /usr/bin/install -c
checking whether build environment is sane... yes
checking for a thread-safe mkdir -p... /bin/mkdir -p
checking for gawk... no
checking for mawk... mawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
.
.
.
checking for strrchr... yes
checking for strstr... yes
checking pcaudiolib/audio.h usability... no
checking pcaudiolib/audio.h presence... no
checking for pcaudiolib/audio.h... no
checking sonic.h usability... no
checking sonic.h presence... no
checking for sonic.h... no
checking for ronn... no
checking that generated files are newer than configure... done
configure: creating ./config.status
config.status: creating Makefile
config.status: creating espeak-ng.pc
config.status: creating config.h
config.status: executing depfiles commands
config.status: executing libtool commands
configure:
Configuration for eSpeak NG complete.
Source code location: .
C99 Compiler: gcc
C99 Compiler flags: -g -O2 -std=c99
Sonic: no
PCAudioLib: no
Klatt: yes
MBROLA: yes
Async: yes
Extended Dictionaries:
Russian: no
Chinese (Mandarin): no
Chinese (Cantonese): noThe eSpeak NG and Speak NG programs, along with the eSpeak NG voices, can then be compiled with make. After this, you should have working, compiled code, but it will only be accessible from the relevant directory (e.g. for me, just a folder on my Desktop).
josh@yoga:~/Desktop/espeak-ng$ make
.
.
.
Mbrola translation file: /home/josh/Desktop/espeak-ng/espeak-data/mbrola_ph/tr1_phtrans -- 14 phonemes
mkdir -p espeak-data/mbrola_ph
ESPEAK_DATA_PATH=/home/josh/Desktop/espeak-ng src/espeak-ng --compile-mbrola=phsource/mbrola/us
Mbrola translation file: /home/josh/Desktop/espeak-ng/espeak-data/mbrola_ph/us_phtrans -- 49 phonemes
mkdir -p espeak-data/mbrola_ph
ESPEAK_DATA_PATH=/home/josh/Desktop/espeak-ng src/espeak-ng --compile-mbrola=phsource/mbrola/us3
Mbrola translation file: /home/josh/Desktop/espeak-ng/espeak-data/mbrola_ph/us3_phtrans -- 47 phonemes
mkdir -p espeak-data/mbrola_ph
ESPEAK_DATA_PATH=/home/josh/Desktop/espeak-ng src/espeak-ng --compile-mbrola=phsource/mbrola/vz
Mbrola translation file: /home/josh/Desktop/espeak-ng/espeak-data/mbrola_ph/vz_phtrans -- 94 phonemes
make[1]: Leaving directory `/home/josh/Desktop/espeak-ng'Finally, we can install eSpeak NG (and make it accessible from anywhere on the computer) with the following command:
josh@yoga:~/Desktop/espeak-ng$ sudo make LIBDIR=/usr/lib/x86_64-linux-gnu install
[sudo] password for josh:
make[1]: Entering directory `/home/josh/Desktop/espeak-ng'
/bin/mkdir -p '/usr/lib'
/bin/sh ./libtool --mode=install /usr/bin/install -c src/libespeak-ng.la '/usr/lib'
libtool: install: /usr/bin/install -c src/.libs/libespeak-ng.so.1.1.48 /usr/lib/libespeak-ng.so.1.1.48
libtool: install: (cd /usr/lib && { ln -s -f libespeak-ng.so.1.1.48 libespeak-ng.so.1 || { rm -f libespeak-ng.so.1 && ln -s libespeak-ng.so.1.1.48 libespeak-ng.so.1; }; })
libtool: install: (cd /usr/lib && { ln -s -f libespeak-ng.so.1.1.48 libespeak-ng.so || { rm -f libespeak-ng.so && ln -s libespeak-ng.so.1.1.48 libespeak-ng.so; }; })
libtool: install: /usr/bin/install -c src/.libs/libespeak-ng.lai /usr/lib/libespeak-ng.la
libtool: install: /usr/bin/install -c src/.libs/libespeak-ng.a /usr/lib/libespeak-ng.a
libtool: install: chmod 644 /usr/lib/libespeak-ng.a
libtool: install: ranlib /usr/lib/libespeak-ng.a
libtool: finish: PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/sbin" ldconfig -n /usr/lib
----------------------------------------------------------------------
Libraries have been installed in:
/usr/lib
If you ever happen to want to link against installed libraries
in a given directory, LIBDIR, you must either use libtool, and
specify the full pathname of the library, or use the `-LLIBDIR'
flag during linking and do at least one of the following:
- add LIBDIR to the `LD_LIBRARY_PATH' environment variable
during execution
- add LIBDIR to the `LD_RUN_PATH' environment variable
during linking
- use the `-Wl,-rpath -Wl,LIBDIR' linker flag
- have your system administrator add LIBDIR to `/etc/ld.so.conf'
See any operating system documentation about shared libraries for
more information, such as the ld(1) and ld.so(8) manual pages.
----------------------------------------------------------------------
/bin/mkdir -p '/usr/bin'
/bin/sh ./libtool --mode=install /usr/bin/install -c src/speak-ng src/espeak-ng '/usr/bin'
libtool: install: /usr/bin/install -c src/speak-ng /usr/bin/speak-ng
libtool: install: /usr/bin/install -c src/.libs/espeak-ng /usr/bin/espeak-ng
make install-exec-hook
make[2]: Entering directory `/home/josh/Desktop/espeak-ng'
cd /usr/bin && rm -f espeak && ln -s espeak-ng espeak
cd /usr/bin && rm -f speak && ln -s speak-ng speak
cd /usr/lib/x86_64-linux-gnu && rm -f libespeak.la && ln -s libespeak-ng.la libespeak.la
make[2]: Leaving directory `/home/josh/Desktop/espeak-ng'
/bin/mkdir -p '/usr/include/espeak'
/usr/bin/install -c -m 644 src/include/espeak/speak_lib.h '/usr/include/espeak'
/bin/mkdir -p '/usr/include/espeak-ng'
/usr/bin/install -c -m 644 src/include/espeak-ng/espeak_ng.h '/usr/include/espeak-ng'
/bin/mkdir -p '/usr/lib/pkgconfig'
/usr/bin/install -c -m 644 espeak-ng.pc '/usr/lib/pkgconfig'
/bin/mkdir -p '/usr/share/vim/addons/ftdetect'
/usr/bin/install -c -m 644 vim/ftdetect/espeakfiletype.vim '/usr/share/vim/addons/ftdetect'
/bin/mkdir -p '/usr/share/vim/addons/syntax'
/usr/bin/install -c -m 644 vim/syntax/espeaklist.vim '/usr/share/vim/addons/syntax'
/bin/mkdir -p '/usr/share/vim/registry'
/usr/bin/install -c -m 644 vim/registry/espeak.yaml '/usr/share/vim/registry'
make install-data-hook
make[2]: Entering directory `/home/josh/Desktop/espeak-ng'
rm -rf /usr/share/espeak-data
mkdir -p /usr/share/espeak-data
cp -prf espeak-data/* /usr/share/espeak-data
make[2]: Leaving directory `/home/josh/Desktop/espeak-ng'
make[1]: Leaving directory `/home/josh/Desktop/espeak-ng'Huzzah! You should now have a functional installation of eSpeak NG! You should be able to use any existing language at this time. Here’s a command to test out the US English version:
josh@yoga:~/Desktop/espeak-ng$ espeak-ng -v en-us --stdout "Hey there, Bermet! What are you doing?" | paplayIf you found this post you probably want to know how to add a new language to eSpeak NG, and that’s what we will start doing now.
Neccesary Files for A New Language
The Voice File
The first file we’re going to add is the so-called “Voice File”. In a nutshell, this is a simple file that defines the language and how that language is to be spoken.
In this file you must define the language name and its two letter code, and then you optionally can specify a male or female voice, define what the pitch should be, and other characteristics of the voice.
This file needs to be located in /espeak-data/voices/family/ where family is the language family of your new language.
Since Kyrgyz is a Turkic language, I’m going to save the voice file in /espeak-data/voices/trk/. The name of the voice file should just be the 2-letter code of the language. That’s ky for Kyrgyz.
I’d recommend looking through the other voice files for other languages to get an idea of what kinds of things you may want to define. There are many options, but to get started all you need to do is define the language name and code.
Here’s how to create and save the most simple voice file with the simple Linux text editor nano.
josh@yoga:~/Desktop/espeak-ng$ cd espeak-data/
josh@yoga:~/Desktop/espeak-ng/espeak-data$ cd voices/
josh@yoga:~/Desktop/espeak-ng/espeak-data/voices$ cd trk/
josh@yoga:~/Desktop/espeak-ng/espeak-data/voices/trk$ nanoOnce you press enter, you should see something like this, and then enter the two lines needed and then WriteOut the file and save.
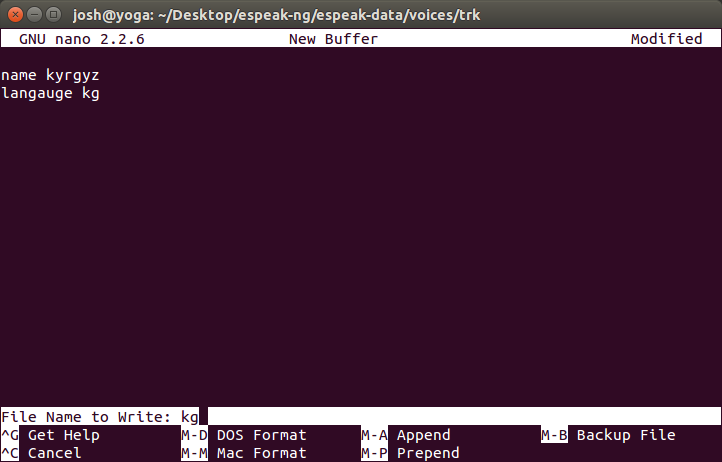
To get more specifics the official documentation on the voice file is very thorough.
Huzzah! We’ve just created one of the five files we need to create.
Phoneme Definition File
We now need to define what the sounds of the new language actually sound like.
That is, if we want to read text out load on the computer, we need to be able to generate an acoustic output that will come out our computer speakers.
We accomplish this by creating a file which defines the acoustic output for each sound (aka for each phoneme). This is called the phoneme definition file.
Here’s a section of my ph_kyrgyz phoneme definition file which defines some of the short vowels:
josh@yoga:~/Desktop/espeak-ng/phsource$ sed -n '20,55p' ph_kyrgyz
// ============ //
// SHORT VOWELS //
// ============ //
phoneme a
ipa ɑ
vowel starttype #i endtype #i
length 200
FMT(vowel/0_3)
endphoneme
phoneme e
ipa e
vowel starttype #e endtype #e
length 170
FMT(vowel/e)
endphoneme
phoneme i
ipa i
vowel starttype #i endtype #i
length 170
IfNextVowelAppend(;)
FMT(vowel/i)
endphoneme
phoneme o
ipa o
vowel starttype #o endtype #o
length 200
FMT(vowel/o_8)
endphonemeMore specifics about the syntax of this file can be found best explained by the official documentation.
In the beginning, however, you can get a long way by just finding similar sounds in other languages, and copy-and-pasting those sounds into your new phoneme definition file.
The Dictionary Files
The dictionary files (which should be saved into the /dictsource directory), are responsible for converting text into sounds (aka phonemes).
Practically all languages are written in a way that is not exact, but we need something extact if we are telling a computer how to read text out-loud.
The dictionary files help us create more precise transcriptions of words. These files take written words and convert them into a phonetic transcription. If these dictionary files work well, we will be able to produce a phonetic transcription for any text. Pretty cool, right?!
The problem is, for almost any ‘regular’ rule we find in a language, there will be ‘exceptions’. This is why there are at least two dictionary files: one for regular rules (ky_rules) and one for exceptions (ky_list).
My rules file for Kyrgyz looks something like this, just showing from lines 33 to 90:
josh@yoga:~/Desktop/espeak-ng/dictsource$ sed -n '33,90p' ky_rules
.L01 а о у ы ё ю я // back vowels
.L02 э е и ө ү // front vowels
.L03 п б д т к г х ш щ ж з с ц ч й л м н ң ф в р ъ ь // any consonant
.L04 а о у ы ё ю я э е и ө ү // all vowels
.group а
а a
аа a:
.group о
о o
оо o:
.group у
у u
уу u:
.group ы
ы I
ыы I:
.group и
и i
ии i:
.group ө
ө O
өө O:
.group ү
ү y
үү y:
.group е
е e
ее e:
.group э
э e
ээ e:
.group к
к (L01 q // syllable onset /k/ followed by back vowel (MAX-ONSET)
к (L02 k // syllable onset /k/ followed by back vowel (MAX-ONSET)
L01) к (L03 q // syllable final /k/ preceded by back vowel
L02) к (L03 k // syllable final /k/ preceded by front vowel
L01) к (_ q // word final /k/ preceded by back vowel
L02) к (_ k // word final /k/ preceded by front vowel
.group г
г (L01 G // syllable onset /g/ followed by back vowel (MAX-ONSET)
г (L02 g // syllable onset /g/ followed by back vowel (MAX-ONSET)
L01) г (L03 G // syllable final /g/ preceded by back vowel
L02) г (L03 g // syllable final /g/ preceded by front vowel
L01) г (_ G // word final /g/ preceded by back vowel
L02) г (_ g // word final /g/ preceded by front vowelYou can see that there are some groups defined at the beginning (e.g. .L01, .L02, etc), and they show up in the rules later on. You can define and use groups like this to make rules about certain contexts.
Some rules can be very simple, like all the rules for vowels seen here.
Every language is going to have different rules, so all I want to do here is give you an idea of what this file does. These rules translate a letter (on the left) to a sound (on the right). In this case, since I’m working on Kyrgyz, all the letters are Cyrillic and all the sounds are represented by Latin letters. Every sound (written in Latin letters) should have a definition in the phoneme definition file.
Now, let’s take a look at my ‘exceptions’ file. In fact, this file includes exceptions as well as definitions of symbols. Numbers have to be defined here as well.
josh@yoga:~/Desktop/espeak-ng/dictsource$ sed -n '25,30p' ky_list
// Numbers
_1 b'ir
_2 ek'i
_3 'ytS
_4 t'Ort
_5 b'eSYou’ll find a much more detailed explaination of these files in the official documentation.
Editing the Master Phoneme File
We now have to link up our specific phoneme file for the new language to the master set of all phonemes. This master file is located at phsource/phonemes.
In the beginning, the file defines common vowels and consonants, and then at the end we find references to individual languages. Here, at the end of the file, is where we should include a reference to our new language.
Before we edit anything, the tail of the file looks like this:
josh@yoga:~/Desktop/espeak-ng$ tail phsource/phonemes
phonemetable om base
include ph_oromo
phonemetable my base
include ph_burmese
phonemetable gn base
include ph_guaraniAfter I make the edit to add a reference to the Kyrgyz language, the file looks like this:
josh@yoga:~/Desktop/espeak-ng/phsource$ tail phonemes
phonemetable my base
include ph_burmese
phonemetable gn base
include ph_guarani
phonemetable ky base
include ph_kyrgyzFor this file, that’s all we have to do!
Editing Makefile.am
This is the point where I ran into some issues. I couldn’t find anywhere on the original documentation a mention of editing the Makefile.am, so I left it alone, did all the other steps, and then ran into lots of issues.
Finally I decided to take a longer look at the Makefile, and I realized that there were a few simple things that needed to be added for my Kyrgyz voice to compile and install correctly.
First, there’s a reference to the phoneme file that should be added:
josh@yoga:~/Desktop/espeak-ng$ sed -n '190,205p' Makefile.am
##### phoneme data:
espeak-data/phondata: phsource/phonemes.stamp
espeak-data/phondata-manifest: phsource/phonemes.stamp
espeak-data/phonindex: phsource/phonemes.stamp
espeak-data/phontab: phsource/phonemes.stamp
espeak-data/intonations: phsource/phonemes.stamp
phsource/phonemes.stamp: \
phsource/ph_afrikaans \
phsource/ph_akan \
phsource/ph_albanian \
phsource/ph_amhari \
phsource/ph_arabic \
phsource/ph_aragon \
phsource/ph_armenian \You see at the end of this section all the listings of the ph_language files? That’s where we need to add a line for our new langauge.
After I add a reference to ph_kyrgyz, the file looks like this:
josh@yoga:~/Desktop/espeak-ng$ sed -n '253,255p' Makefile.am
phsource/ph_kurdish \
phsource/ph_kyrgyz \
phsource/ph_latin \Second, we can file in the Makefile.am references to all the dictionary files for the existing languages. Likewise, we have to add a reference to our dictionary file:
josh@yoga:~/Desktop/espeak-ng$ sed -n '305,315p' Makefile.am
##### dictionaries:
dictionaries: \
espeak-data/af_dict \
espeak-data/am_dict \
espeak-data/an_dict \
espeak-data/as_dict \
espeak-data/az_dict \
espeak-data/bg_dict \
espeak-data/bn_dict \I made the change, adding ky_dict, and I get this:
josh@yoga:~/Desktop/espeak-ng$ sed -n '347,349p' Makefile.am
espeak-data/ku_dict \
espeak-data/ky_dict \
espeak-data/la_dict \Thirdly, we can find a list of definitions putting all the language information together to compile the dictionary:
josh@yoga:~/Desktop/espeak-ng$ sed -n '386,404p' Makefile.am
af: espeak-data/af_dict
dictsource/af_extra:
touch dictsource/af_extra
espeak-data/af_dict: src/espeak-ng phsource/phonemes.stamp dictsource/af_list dictsource/af_rules dictsource/af_extra
cd dictsource && ESPEAK_DATA_PATH=$(PWD) LD_LIBRARY_PATH=../src:${LD_LIBRARY_PATH} ../src/espeak-ng --compile=af && cd ..
am: espeak-data/am_dict
dictsource/am_extra:
touch dictsource/am_extra
espeak-data/am_dict: src/espeak-ng phsource/phonemes.stamp dictsource/am_list dictsource/am_rules dictsource/am_extra
cd dictsource && ESPEAK_DATA_PATH=$(PWD) LD_LIBRARY_PATH=../src:${LD_LIBRARY_PATH} ../src/espeak-ng --compile=am && cd ..
an: espeak-data/an_dict
dictsource/an_extra:
touch dictsource/an_extra
espeak-data/an_dict: src/espeak-ng phsource/phonemes.stamp dictsource/an_list dictsource/an_rules dictsource/an_extra
cd dictsource && ESPEAK_DATA_PATH=$(PWD) LD_LIBRARY_PATH=../src:${LD_LIBRARY_PATH} ../src/espeak-ng --compile=an && cd ..Likewise, we need these instructions for our new language. For Kyrgyz, I added the same definitions and I get this:
josh@yoga:~/Desktop/espeak-ng$ sed -n '620,638p' Makefile.am
ku: espeak-data/ku_dict
dictsource/ku_extra:
touch dictsource/ku_extra
espeak-data/ku_dict: src/espeak-ng phsource/phonemes.stamp dictsource/ku_list dictsource/ku_rules dictsource/ku_extra
cd dictsource && ESPEAK_DATA_PATH=$(PWD) LD_LIBRARY_PATH=../src:${LD_LIBRARY_PATH} ../src/espeak-ng --compile=ku && cd ..
ky: espeak-data/ky_dict
dictsource/ky_extra:
touch dictsource/ky_extra
espeak-data/ky_dict: src/espeak-ng phsource/phonemes.stamp dictsource/ky_list dictsource/ky_rules dictsource/ky_extra
cd dictsource && ESPEAK_DATA_PATH=$(PWD) LD_LIBRARY_PATH=../src:${LD_LIBRARY_PATH} ../src/espeak-ng --compile=ky && cd ..
la: espeak-data/la_dict
dictsource/la_extra:
touch dictsource/la_extra
espeak-data/la_dict: src/espeak-ng phsource/phonemes.stamp dictsource/la_list dictsource/la_rules dictsource/la_extra
cd dictsource && ESPEAK_DATA_PATH=$(PWD) LD_LIBRARY_PATH=../src:${LD_LIBRARY_PATH} ../src/espeak-ng --compile=la && cd ..With these final three changes to Makefile.am, you should be ready to go!
Conclusion
If you’ve gone through all these steps successfully, you should be ready to start making updates to the various language definition files.
Whenever you make an update, (for instance to a file like ph_kyrgyz) you should be able to quickly listen to your changes by re-running the make and sudo make install commands.
josh@yoga:~/Desktop/espeak-ng$ makeAnd then
josh@yoga:~/Desktop/espeak-ng$ sudo make installThere shouldn’t be a need to re-run ./autogen.sh or ./configure, as far as I can tell.
My workflow has been (1) make a change, (2) run make and sudo make install, (3) listen to change, (4) go back to (1).
I hope you found this post useful!
If you have any questions or comments or find an issue, you can email me or leave a comment!