Create New Voice with Ossian & Merlin
Introduction
Ossian is a collection of Python code for building text-to-speech (TTS) systems. We’ve designed Ossian to make research on TTS more efficient and at the same time more attainable for newcomers to TTS. With Ossian you can quickly script your ideas and run experiments, spending more time working on TTS and less time worrying about all the rest.
Ossian supports the use of neural nets trained with the Merlin toolkit as duration and acoustic models. You can also use the HTS toolkit to build HMM-GMM models.
Work on Ossian started with funding from the EU FP7 Project Simple4All.
All comments and feedback are very welcome! Make a fork, add to the code and send us a pull request!
Dependencies
Before we can get started with Ossian, let’s download and install its dependencies. Thankfully, there aren’t too many, and they’re all very easy to get working fast.
HTK
Ossian requires HTK to generate the alignments for training your DNN in Merlin. To get access to HTK, you need to register an account with the University of Cambridge. Thankfully, registration is really easy! Just go to this link:
http://htk.eng.cam.ac.uk/register.shtml
Fill out some information:
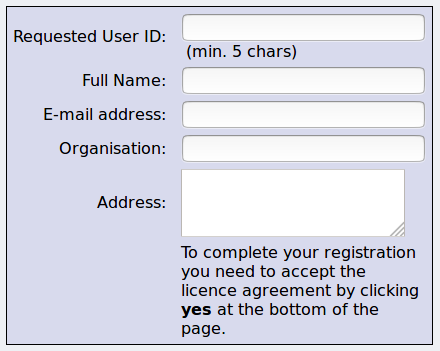
And accept the terms of the license:

You will receive your password in a very short email from htk-mgr@eng.cam.ac.uk that looks something like this:
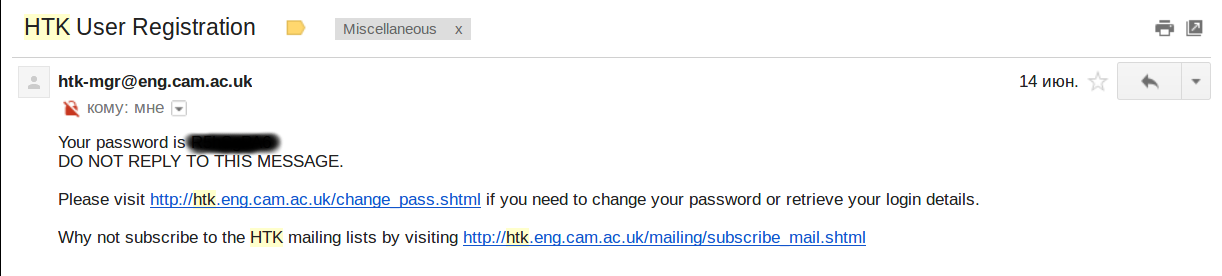
The password you receive will be some random string, so if you prefer a password that isn’t gibberish, you can easily change it here: http://htk.eng.cam.ac.uk/change_pass.shtml.
At this point, don’t worry about downloading HTK yourself. Soon, we will take your beautiful new username and password and feed them into Ossian’s installation script. The installation script is designed to take care of all the downloading, compilation and formatting for HTK, so you don’t have to! This means less time worrying about file structure and more time working on speech synthesis!
Compilation Dependencies
These are some dependencies you may need for compiling Ossian on Linux:
sudo apt-get install clang libsndfile1-dev gsl-bin libgsl0-dev libconfig-devPython Dependencies
Next we will install some Python dependencies:
# for Ossian
sudo pip install numpy scipy regex argparse lxml scikit-learn regex configobj
# for Merlin
sudo pip install bandmat theano matplotlibThat’s it! You should be good to go on dependencies.
Install Ossian
Now we’re ready to install Ossian itself! Huzzah! First let’s clone Ossian from github, then compile it.
Clone Ossian
josh@yoga:~/git$ git clone https://github.com/CSTR-Edinburgh/Ossian.git
Cloning into 'Ossian'...
remote: Counting objects: 377, done.
remote: Compressing objects: 100% (5/5), done.
remote: Total 377 (delta 0), reused 1 (delta 0), pack-reused 372
Receiving objects: 100% (377/377), 389.73 KiB | 229.00 KiB/s, done.
Resolving deltas: 100% (154/154), done.
Checking connectivity... done.Compile Ossian
Our configuration and compiling will be done by the ./tools/setup_tools.sh script. This script takes two arguments, HTK_USERNAME and HTK_PASSWORD.
In fact this one script will download and compile both HTK and Merlin in addition to Ossian.
josh@yoga:~/git/Ossian$ ./scripts/setup_tools.sh HTK_USERNAME HTK_PASSWORD
Cloning into 'merlin'...
remote: Counting objects: 2568, done.
remote: Compressing objects: 100% (75/75), done.
remote: Total 2568 (delta 27), reused 54 (delta 17), pack-reused 2474
Receiving objects: 100% (2568/2568), 5.74 MiB | 217.00 KiB/s, done.
Resolving deltas: 100% (1360/1360), done.
Checking connectivity... done.
HEAD is now at 8aed278 Merge pull request #149 from shartoo/master
mkdir -p ./build/objs
g++ -O1 -g -Wall -fPIC -Isrc -o "build/objs/cheaptrick.o" -c "src/cheaptrick.cpp"
mkdir -p ./build/objs
g++ -O1 -g -Wall -fPIC -Isrc -o "build/objs/common.o" -c "src/common.cpp"
mkdir -p ./build/objs
g++ -O1 -g -Wall -fPIC -Isrc -o "build/objs/d4c.o" -c "src/d4c.cpp"
mkdir -p ./build/objs
g++ -O1 -g -Wall -fPIC -Isrc -o "build/objs/dio.o" -c "src/dio.cpp"
mkdir -p ./build/objs
g++ -O1 -g -Wall -fPIC -Isrc -o "build/objs/fft.o" -c "src/fft.cpp"
mkdir -p ./build/objs
.
.
.
make[2]: Nothing to be done for 'install-data-am'.
make[2]: Leaving directory '/home/josh/git/Ossian/tools/downloads/SPTK-3.6/script'
make[1]: Leaving directory '/home/josh/git/Ossian/tools/downloads/SPTK-3.6/script'
make[1]: Entering directory '/home/josh/git/Ossian/tools/downloads/SPTK-3.6'
make[2]: Entering directory '/home/josh/git/Ossian/tools/downloads/SPTK-3.6'
make[2]: Nothing to be done for 'install-exec-am'.
test -z "/home/josh/git/Ossian/scripts/..//tools/include" || /bin/mkdir -p "/home/josh/git/Ossian/scripts/..//tools/include"
/usr/bin/install -c -m 644 'include/SPTK.h' '/home/josh/git/Ossian/scripts/..//tools/include/SPTK.h'
make[2]: Leaving directory '/home/josh/git/Ossian/tools/downloads/SPTK-3.6'
make[1]: Leaving directory '/home/josh/git/Ossian/tools/downloads/SPTK-3.6'
164This script has compiled Ossian, cloned and compiled Merlin, downloaded and compiled HTK, and put everything in the tools directory. At this point, if you didn’t run into any problems, you should have a working installation of Ossian which can call both Merlin and HTK.
Run the Demo
The CSTR folks have been nice enough to provide a small corpus for the Romanian langauge. To run the Ossian demo, we will download this corpus which is just made of audio files and their transcripts.
Get Some Data
First let’s download the CSTR corpus:
josh@yoga:~/git/Ossian$ wget https://www.dropbox.com/s/uaz1ue2dked8fan/romanian_toy_demo_corpus_for_ossian.tar?dl=0
--2017-09-15 20:25:48-- https://www.dropbox.com/s/uaz1ue2dked8fan/romanian_toy_demo_corpus_for_ossian.tar?dl=0
Resolving www.dropbox.com (www.dropbox.com)...
162.125.66.1, 2620:100:6022:1::a27d:4201
Connecting to www.dropbox.com (www.dropbox.com)|162.125.66.1|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://dl.dropboxusercontent.com/content_link/ILEKh6O8DyAngFvbzynnhdJJEjlWXfqsE1fcBe6IFwdWAqcYcoTJ31Wg4rNSZG0t/file [following]
--2017-09-15 20:25:54-- https://dl.dropboxusercontent.com/content_link/ILEKh6O8DyAngFvbzynnhdJJEjlWXfqsE1fcBe6IFwdWAqcYcoTJ31Wg4rNSZG0t/file
Resolving dl.dropboxusercontent.com (dl.dropboxusercontent.com)... 162.125.66.6, 2620:100:6022:6::a27d:4206
Connecting to dl.dropboxusercontent.com (dl.dropboxusercontent.com)|162.125.66.6|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 8499200 (8.1M) [application/x-tar]
Saving to: ‘romanian_toy_demo_corpus_for_ossian.tar?dl=0’
romanian_toy_demo_corpus_for_ossian.tar?dl=0 100%[================================================================================================================>] 8.11M 234KB/s in 39s
2017-09-15 20:26:36 (213 KB/s) - ‘romanian_toy_demo_corpus_for_ossian.tar?dl=0’ saved [8499200/8499200]Now we need to unpack the compressed corpus:
josh@yoga:~/git/Ossian$ tar xvf romanian_toy_demo_corpus_for_ossian.tar\?dl\=0
corpus/rm/speakers/rss_toy_demo/
corpus/rm/speakers/rss_toy_demo/README
corpus/rm/speakers/rss_toy_demo/txt/
corpus/rm/speakers/rss_toy_demo/txt/adr_diph1_001.txt
corpus/rm/speakers/rss_toy_demo/txt/adr_diph1_002.txt
corpus/rm/speakers/rss_toy_demo/txt/adr_diph1_003.txt
.
.
.
corpus/rm/speakers/rss_toy_demo/wav/adr_diph1_027.wav
corpus/rm/speakers/rss_toy_demo/wav/adr_diph1_028.wav
corpus/rm/speakers/rss_toy_demo/wav/adr_diph1_029.wav
corpus/rm/text_corpora/
corpus/rm/text_corpora/wikipedia_10K_words/
corpus/rm/text_corpora/wikipedia_10K_words/text.txtNow let’s take a look at the file structure of this Romanian corpus. When building your own language, you should have your file structure be exactly the same.
josh@yoga:~/git/Ossian$ tree corpus/
corpus/
└── rm
├── speakers
│ └── rss_toy_demo
│ ├── README
│ ├── txt
│ │ ├── adr_diph1_001.txt
│ │ ├── adr_diph1_002.txt
│ │ └── adr_diph1_003.txt
│ └── wav
│ ├── adr_diph1_001.wav
│ ├── adr_diph1_002.wav
│ └── adr_diph1_003.wav
└── text_corpora
└── wikipedia_10K_words
└── text.txt
7 directories, 60 filesI’m only showing a few audio (*.wav) and text (*.txt) files here, but you get the idea. The filenames for each utterance and its transcript are the same. You see we have a adr_diph1_001.wav as well as a adr_diph1_001.txt. If you have mismatches or missing files, you will have issues later on in training.
For this demo, remember that we’re working with the Romainian language, hence the main directory label rm for “Romainian”. One level down we have a speakers directory and a text_corpora directory. We can have multiple speakers (i.e. voices) per language, so you can imagine having multiple subdirs under speakers/*, one for each voice or corpus. Here the speaker dir we’re working with is labeled rss_toy_demo, but it could easily be called mary or john for the actual speaker’s name.
Next, we have a text corpus directory called text_corpora. We could have multiple text corpora (just like we could have multiple speakers), but in our case we’re just working with a sample of Romainian Wikipedia, hence the filename wikipedia_10k_words.
So, now that we’ve downloaded our data and taken a look, let’s use it to make a speech synthesizer!
Train Ossian Model
There’s a main Ossian train.py script which takes three main arguments:
- the speaker dir name after the
-sflag:-s speaker_dir - the language dir name after the
-lflag:-l language_dir - the recipe configuration file name (without extention):
naive_01_nn
josh@yoga:~/git/Ossian$ python ./scripts/train.py -s rss_toy_demo -l rm naive_01_nn
-- Gather corpus
-- Train voice
/home/josh/git/Ossian/train//rm/speakers/rss_toy_demo/naive_01_nn
/home/josh/git/Ossian/voices//rm/rss_toy_demo/naive_01_nn
try loading config from python...
/home/josh/git/Ossian/recipes/naive_01_nn.cfg
.
.
.
Applying processor dnn_labelmaker
p p p p p p p pp p p p p pp p p p p p pp p p p p p p p
== Train voice (proc no. 13 (acoustic_predictor)) ==
Train processor acoustic_predictor
Training of NNAcousticPredictor itself not supported within Ossian --
use Merlin to train on the prepared data
------------
Wrote config file to:
/home/josh/git/Ossian/train//rm/speakers/rss_toy_demo/naive_01_nn/processors/acoustic_predictor/config.cfg
Edit this config file as appropriate and use for training with Merlin.
In particular, you will want to increase training_epochs to train real voices
You will also want to experiment with learning_rate, batch_size, hidden_layer_size, hidden_layer_type
To train with Merlin and then store the resulting model in a format suitable for Ossian, please do:
cd /home/josh/git/Ossian
export THEANO_FLAGS= ; python ./tools/merlin/src/run_merlin.py /home/josh/git/Ossian/train//rm/speakers/rss_toy_demo/naive_01_nn/processors/acoustic_predictor/config.cfg
python ./scripts/util/store_merlin_model.py /home/josh/git/Ossian/train//rm/speakers/rss_toy_demo/naive_01_nn/processors/acoustic_predictor/config.cfg /home/josh/git/Ossian/voices/rm/rss_toy_demo/naive_01_nn/processors/acoustic_predictor
------------
Applying processor acoustic_predictor
p p p p p pp p p p p p pp p p p p p p pp p p p p p p pTrain Merlin Model
To train fancy-dancy DNNs for our speech synthesizer, we can use Merlin (built on top of Theano).
We’re going to train both an acoustic and duration model here. Since this is a Ossian demo and not Merlin, we aren’t going to get into detail on Merlin, but if you’re interested, here’s a beginner’s Merlin walkthrough.
Just run the following commands:
josh@yoga:~/git/Ossian$ export THEANO_FLAGS=""
# train duration model
josh@yoga:~/git/Ossian$ python ./tools/merlin/src/run_merlin.py /home/josh/git/Ossian/train/rm/speakers/rss_toy_demo/naive_01_nn/processors/duration_predictor/config.cfg
# train acoustic model
josh@yoga:~/git/Ossian$ python ./tools/merlin/src/run_merlin.py /home/josh/git/Ossian/train/rm/speakers/rss_toy_demo/naive_01_nn/processors/acoustic_predictor/config.cfgStore Merlin Model
Now we will take the Merlin DNNs we just made and format them for Ossian. NB - if you trained your DNNs on a GPU machine, they can only be used on a GPU machine.
We call the conversion script with:
- the same config file you used for training:
config.cfg - the directory name for newly formatted model:
acoustic_predictororduration_predictor
# store duration model
josh@yoga:~/git/Ossian$ python ./scripts/util/store_merlin_model.py /home/josh/git/Ossian/train/rm/speakers/rss_toy_demo/naive_01_nn/processors/duration_predictor/config.cfg /home/josh/git/Ossian/voices/rm/rss_toy_demo/naive_01_nn/processors/duration_predictor
# store acoustic model
josh@yoga:~/git/Ossian$ python ./scripts/util/store_merlin_model.py /home/josh/git/Ossian/train/rm/speakers/rss_toy_demo/naive_01_nn/processors/acoustic_predictor/config.cfg /home/josh/git/Ossian/voices/rm/rss_toy_demo/naive_01_nn/processors/acoustic_predictorSynthesize New Audio
Now you’ve got everything in place to synthesize some speech with Ossian! We can use a sample Romainian sentence (text) provided by CSTR to make a sample as such:
josh@yoga:~/git/Ossian$ mkdir ./test/wav/
josh@yoga:~/git/Ossian$ python ./scripts/speak.py -l rm -s rss_toy_demo -o ./test/wav/romanian_test.wav naive_01_nn ./test/txt/romanian.txt
/home/josh/git/Ossian/train//rm/speakers/rss_toy_demo/naive_01_nn
/home/josh/git/Ossian/voices//rm/rss_toy_demo/naive_01_nn
try loading config from python...
/home/josh/git/Ossian/voices//rm/rss_toy_demo/naive_01_nn/voice.cfg
.
.
.
== proc no. 7 (duration_predictor) ==
p 1
2
3
4
== proc no. 8 (dnn_labelmaker) ==
p
== proc no. 9 (acoustic_predictor) ==
p 1
2
3
4
5
6
7
mgc
vuv
lf0
bap
/home/josh/git/Ossian//tools/bin//x2x +fd /tmp/tmp.mgc >/tmp/tmp_d.mgc
/home/josh/git/Ossian//tools/bin//x2x +fd /tmp/tmp.vuv >/tmp/tmp_d.vuv
/home/josh/git/Ossian//tools/bin//x2x +fd /tmp/tmp.lf0 >/tmp/tmp_d.lf0
/home/josh/git/Ossian//tools/bin//x2x +fd /tmp/tmp.bap >/tmp/tmp_d.bap
/home/josh/git/Ossian//tools/bin//mgc2sp -a 0.77 -g 0 -m 59 -l 2048.0 -o 2 /tmp/tmp.mgc | /home/josh/git/Ossian//tools/bin//sopr -d 32768.0 -P | /home/josh/git/Ossian//tools/bin//x2x +fd -o > /tmp/tmp.spec
/home/josh/git/Ossian//tools/bin//synth 2048.0 48000 /tmp/tmp_d.lf0 /tmp/tmp.spec /tmp/tmp_d.bap /tmp/tmp.resyn.wav
complete /tmp/tmp.resyn.wav.
Produced /home/josh/git/Ossian/voices//rm/rss_toy_demo/naive_01_nn/output/wav/temp.wav
Warning: no lab produced for this utt
--> took 4.04 secondsAnd there you go! You can listen to your beautiul new Romainian speech in the file ./test/wav/romanian_test.wav.
Conclusion
That was pretty easy, yeah? The goal of Ossian is to make good research and development easier, so you can quickly test out more TTS systems. If you have ideas on how to make Ossian better, let us know:)
Resources
Here’s a tutorial on Statistical parametric speech synthesis writen by Simon King, one of the creators of Merlin.